SS2023 Project - Deep Learning Model Compression Techniques for High Speed Object Detection
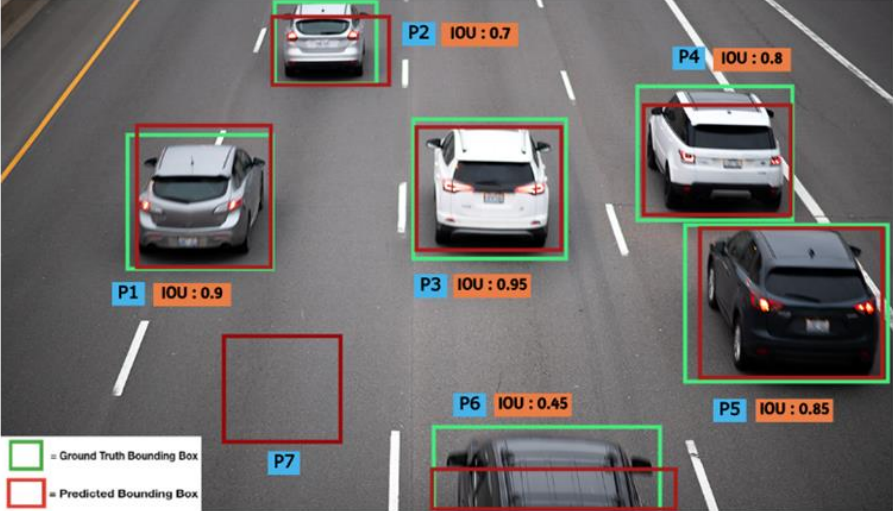
High Speed Object Detection
Supervisor: Talha Uddin Sheikh
Study and implementation of different pruning and quantization techniques for deep learning model compression for state of the art object detection models.
Tasks
- Study of different pruning methods for deep learning models
- Study of different quantization methods for deep learning models
- Implementation of different pruning and quantization methods on a state of the art object detection model
- Experimentation and benchmarking
Related Literature
[1] Helms, D., Amende, K., Bukhari, S., de Graaff, T., Frickenstein, A., Hafner, F., … & Vemparala, M. R. (2021, July). Optimizing Neural Networks for Embedded Hardware. In SMACD/PRIME 2021; International Conference on SMACD and 16th Conference on PRIME (pp. 1-6). VDE.
[2] Hawks, B., Duarte, J., Fraser, N. J., Pappalardo, A., Tran, N., & Umuroglu, Y. (2021). Ps and qs: Quantization-aware pruning for efficient low latency neural network inference. Frontiers in Artificial Intelligence, 4, 676564.
[3] Hubara, I., Courbariaux, M., Soudry, D., El-Yaniv, R., & Bengio, Y. (2017). Quantized neural networks: Training neural networks with low precision weights and activations. The Journal of Machine Learning Research, 18(1), 6869-6898.
Subscribe
Subscribe to this blog via RSS.
Recent Posts
- SS2023 Project - Deep Learning Model Compression Techniques for High Speed Object Detection Saif Khan (03 Apr 2023)
- SS2023 Project - Optimize a Human Pose Estimation Network using Knowledge Distillation Saif Khan (03 Apr 2023)
- SS2023 Project - Object Detection in Videos Saif Khan (03 Apr 2023)
- Successful Ovation Summer Academy 2017 Marcus Liwicki (22 Sep 2017)
Popular Tags
intro fun official lecture very deep learning publications ijcnn arxiv events mindstorm object detection pose estimation